Intro
TextCNN is a good case demonstrating how neural-network could not only learn from the data, but also do the feature extraction for us.
In Indeed we got bunch of text data from our user, like resume, job-description, company related content like reviews and Q&A. These user-generated-content is our most valuable asset. To help people get good jobs we’re constantly trying better way to learn more from these text data.
Here’s the slide:
The concept of TextCNN
- taking the concatenated word embeddings of a sentence or article as pixels
- use filters to learn extracting features out of them
- then use a max-pooling layer to aggregate all the features
- Finally, learn from those features by the final fully-connected layers.
If you prefer it explained in code
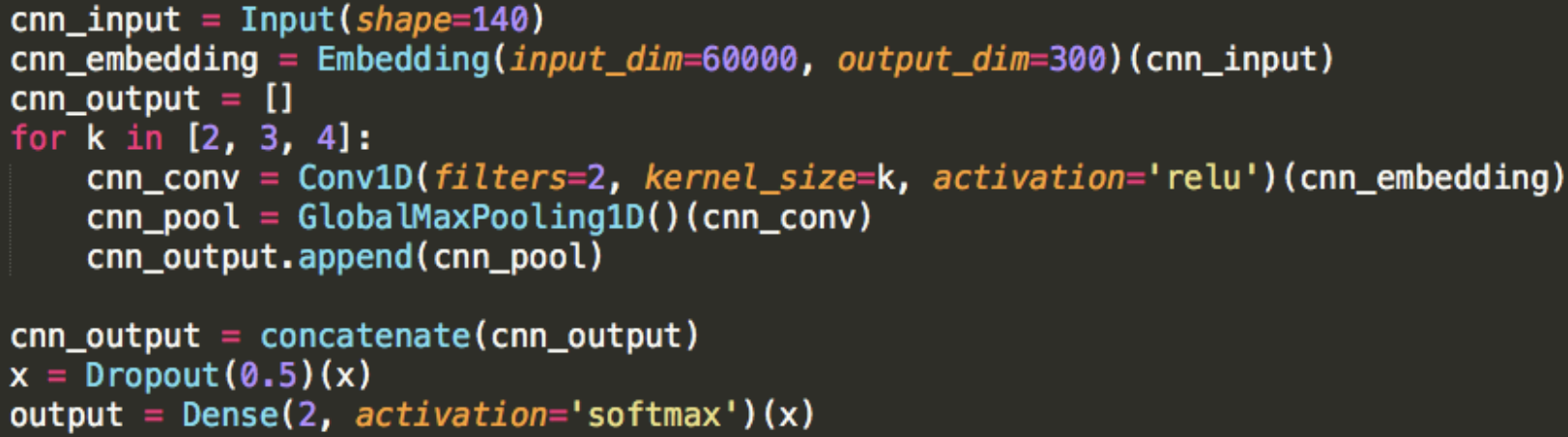
Let’s say we limit our input paragraph length as 140 words.
For the parameters of embedding layer, 60k is the number of top words I usually use for learning English, which means we’re using a English dictionary only contains 60k most frequently used words. But I think it’s more like a upper-bound, you could really start with 10k or 30k should be fine.
The embedding dimension is 300 because I use the pre-trained embedding “FastText” trained from wiki data by Facebook in 2017. Again it’s also a pretty large one, you could find GloVe which is in 128 dimension. I prefer FastText just because I like new stuff, and the idea behind it is fancy.
If you wanna try your own embedding, there is a rule-of-thumb in a 2017 Google Blog saying It’s better be the 4th root of your dictionary size. I have no luck on training it myself and beat using pre-trained one, so I don’t know whether it’s a good rule. But people say you could try from 64 to 1024.
Then for the filters, we got 3 different stride size: [2, 3, 4]. So for each of them we have corresponding 1d-convolution layer with 2 filters, and the MaxPool layer is just taking maximum value from convolution result.
Finally all the output of MaxPool layer will be concatenated into a vector, learn by the final multi-layer-perceptron.
The dropout probability being 0.5 because Hinton said so. Usually it likely being the best or close to. (Except those very aggressive dropout like input dropout or embedding dropout.)
Next steps
Now you know TextCNN, but one of the merit of neural network architecture is, you could easily combine different models and make them trained together.
For example if you feel the jobTitle out of resume is something worth emphasizing on, you could make a dedicated TextCNN model and concatenate the vector before the final multi-layer-perceptron, and then learn from this large vector like they’re all extracted features from different models.
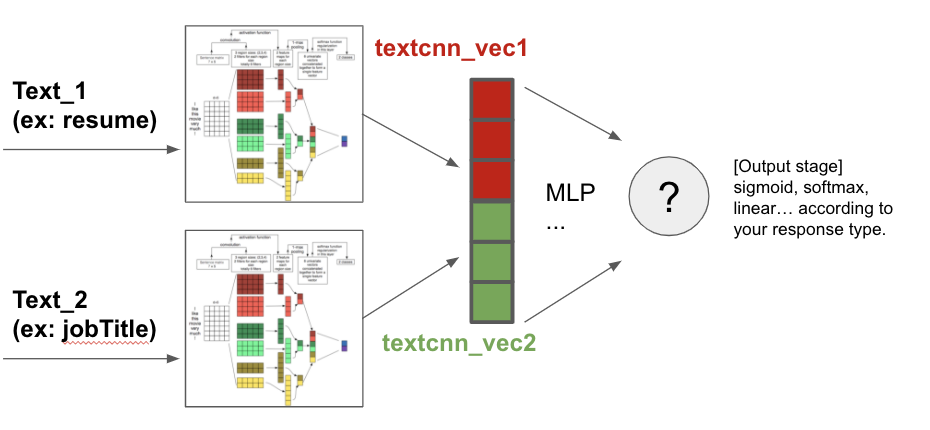
Also, if you feel you’re so good at feature engineering and pretty sure you have some feature that model just can’t be better than you. You could also concatenate your manual crafted features into this big feature vector, make them learned together.

Why you should try it
First, we’re expecting it brings good performance, since mostly n-gram usually would be the main feature for learning from text, and TextCNN is doing a much better job than n-gram.
It’s using embedding so the resolution is much better than word level, and it works not just the exact same words, but also for similar meaning words. And it’s training these feature-learning process, including the embedding and convolution filters during the supervised-learning process to make them specifically fit your data, your purpose.
Also since we’re not doing feature extraction by ourself, we don’t need to explicitly doing them while deploying. Thus we save both the develop time and the computing cost of feature extracting. Besides many fancy features, for examples like features comes from unsupervised learning methods like LDA, NMF, or some indirect usage of embeddings.
Finally you could steal from the giants by using the pretrained embeddings like word2vec, Glove or FastText. It could give you a boost, and especially helpful if you just don’t really got at least millions of samples to learn the embedding all by yourself.
Also, there are some merits natively comes from it just because it’s neural network model.
Previously if we want to train an ensemble model, you have to use some indirect ways like saving all the cross-validation results and make them as input of the 2nd pipeline model to train on their outputs.
In neural network you could ensemble whatever layers you like into one graph, and just train them together from the very beginning. Like, if you just can’t decide you want use RNN or CNN, you could encode your text data by both of them and concatenate them together!
Deployment in Java
The keras model, while backed by tensorflow, could be dumped as tensorflow graph and imported in Java. So you don’t need to deploy it as a service in python, then called by Java and worry about handling the exceptions of communication or service accessibility or reliability.
And the Java code is super easy, like this:

1st you import the model in one line. 2nd you give it the input, which is the tokenized text. 3rd you get the predicted results, and this prediction could be called in batch.
That’s all. Everything is maintained in-process, no feature engineering, no http or boxcar request.